If your codebase is old enough to cause embarrassment in engineering interviews, you have probably had this conversation. Someone pitches a complete rewrite. Someone else argues it is too risky. A third person suggests doing it incrementally. The meeting ends without a decision. Three months later, the same thing happens again.
This is common with legacy JavaScript codebases that have outgrown their original framework. This is not a how-to guide for wrapping JSX components. It is a decision framework for the engineering leader who has to decide whether modernizing a legacy stack makes sense at all, and if it does, which path will not derail the team halfway through.
How to Migrate a Legacy Frontend to React
The most reliable approach for migrating a legacy frontend to React is incremental migration using the Strangler Fig pattern. You run the old and new systems in parallel behind a routing layer, build new features in React, and retire legacy views one slice at a time. Full rewrites are justified only when the codebase has no modular boundaries, the old framework cannot coexist with React, or both scope and deadline are fully locked. Most mid-sized projects take 6 to 12 months with incremental migration; large enterprise systems take 12 to 24 months. The decision depends on codebase modularity, team size, and whether the legacy system is still serving active users.
Does Your Codebase Actually Qualify for Modernization?
Before any framework conversation happens, get clear on what you are actually dealing with. Legacy modernization is not always the right call. The signal is not how old the application is; it is how much it is costing you.
Three questions that give you a quick read:
- Are engineers slower than they should be? If onboarding a new developer takes four weeks because the application runs on a framework nobody has touched in five years, that is a measurable cost. If a simple UI change requires touching ten files because there is no component model, that is a measurable cost.
- Is hiring getting harder? Posting for AngularJS or Backbone.js engineers in 2026 dramatically narrows your pool. The component-based JavaScript ecosystem has the largest developer community globally, with over 11 million websites now built on it. That is a hiring constraint, not a trend.
- Is the framework still actively maintained? AngularJS reached end-of-life in December 2021. jQuery is technically alive but has no meaningful ecosystem development. If your stack is not getting security patches, that is not technical debt; it is a compliance risk.
If two or more of these apply, the frontend modernization conversation is legitimate. If none do, the pressure to move is probably coming from developer preference, not business need. That distinction matters before you commit six to eighteen months of legacy code migration effort to this.
Why the Big Bang Rewrite Keeps Failing Engineering Teams
When teams finally commit to modernizing a legacy codebase, the instinct is almost always to rebuild from scratch. It feels cleaner. You get to make the right architecture decisions this time. No inherited mess from whoever wrote the original application.
In practice, full rewrites are one of the most reliable ways to derail a modernization effort. McKinsey's research finds that fewer than 30% of digital transformations hit their targets, and a meaningful chunk of those failures trace back to the big-bang approach. Here is why it keeps happening:
- Rebuilds take two to three times longer than estimated, almost without exception
- The old system keeps receiving new features in parallel, so the new build is permanently chasing a moving target
- The replacement ends up inheriting the same architectural assumptions as the old one, just written in a newer library
- Teams run out of momentum when there is nothing shipping for months and stakeholders start asking questions
The instinct makes sense. The outcome rarely does. And there is a more reliable default.
The Strangler Fig Pattern: The Safer Default for Legacy Code Migration
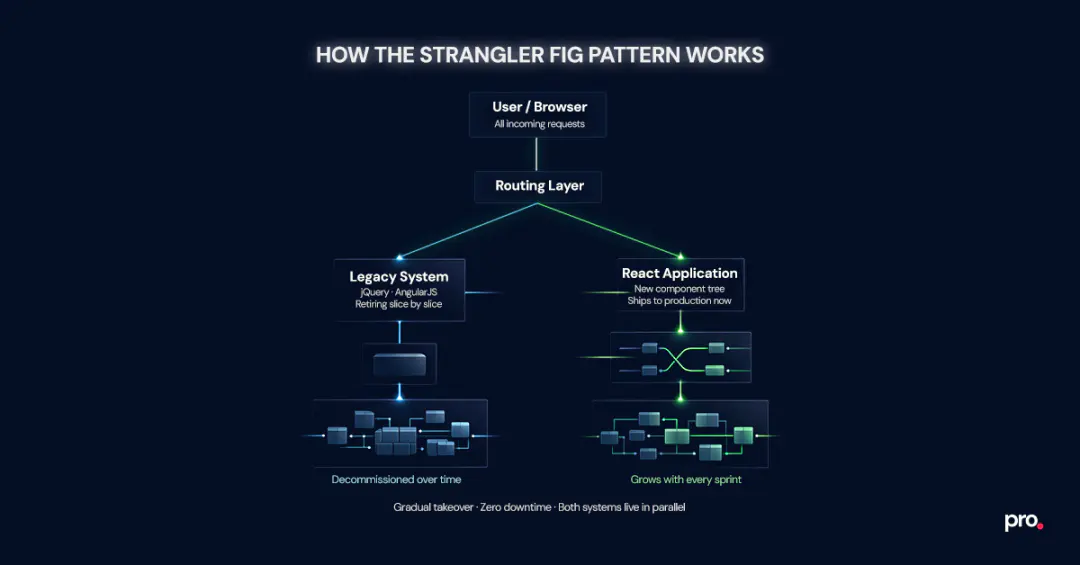
The Strangler Fig pattern is the most dependable approach for legacy code migration in systems that are still live and actively used. It works by running the old interface and the modernized application in parallel: a routing layer, usually an API gateway or a reverse proxy, that decides which requests go to the old stack and which go to the new one. New features are built in the target framework. Old views are retired slice by slice until the existing system has nothing left to serve.
The name comes from a vine that gradually grows around a host tree, drawing nutrients until the original tree is gone and the vine stands on its own, as coined by Martin Fowler in his original write-up on the pattern. The metaphor is more accurate than "migration," which implies a discrete move. This is not a move. It is a gradual takeover.
For teams working with us on React development, applying this pattern means the new component tree grows alongside the old one, not after it is decommissioned. That changes the risk profile significantly, and it is the reason most engagements start here rather than with a rewrite.
Why most teams are better off with this approach:
- New components reach production immediately, before the full changeover is complete
- The existing application stays live throughout, with no disruption for users
- If something breaks in a new slice, the blast radius is contained to that slice
- Engineers build fluency in the new stack gradually, rather than needing to be experts on day one
The tradeoff is real: you are running two systems simultaneously, which adds maintenance overhead, deployment complexity, and cognitive load. For most teams, that cost is still lower than the cost of a rewrite that runs out of runway.
On the infrastructure side, the routing layer is typically a reverse proxy (Nginx, Traefik) or an API gateway that directs traffic between the old and new systems based on URL path. For teams with multiple frontend apps or micro-frontends, Module Federation (Webpack 5+) allows the legacy shell and new React modules to share dependencies at runtime without requiring a full rebuild. Shared authentication middleware between the two systems needs to be resolved before the first slice goes live, not after.
When a Full Rewrite Is the More Defensible Choice
Incremental migration via the Strangler Fig is not always the right answer. There are specific scenarios where rebuilding from scratch is the more defensible approach:
Strangler Fig vs Full Rewrite: A Quick Comparison
| Strangler Fig (Incremental) | Full Rewrite | |
|---|---|---|
| Risk | Lower. Each slice is independently deployable and reversible | Higher. Nothing ships until the full build is complete |
| Timeline | Longer calendar time, but value ships early | Shorter target, but estimates typically miss by 2 to 3x |
| Team size needed | Works with small teams (4 to 6 engineers) | Requires a larger team to staff parallel tracks |
| Best when | System is live, modular, and receiving new features | Codebase is monolithic, framework blocks coexistence, or scope is locked |
| Main tradeoff | Running two systems adds maintenance and cognitive load | No production output for months; stakeholder patience erodes |
The codebase has no modular boundaries. Some older applications genuinely cannot be sliced. If every page is a 4,000-line file with global state wired directly through the DOM, there is no clean unit to extract and replace. You cannot strangle what has no separable parts.
The old framework blocks coexistence. Early versions of AngularJS and some proprietary templating systems cannot run alongside a modern component-based tool without a significant bridging layer. When the effort to build that bridge approaches the effort of a full rebuild, the incremental approach loses its cost argument.
Scope is fully locked and deadline is fixed. If the application is being replaced as part of a defined product launch, not evolved alongside an active system, and requirements are genuinely locked, a rebuild can be scoped and delivered. The critical word is "locked." Open-ended rewrites are still high risk. Locked-scope rewrites are just builds.
The team is large enough to run two tracks. A four-person team cannot maintain an old system and run a parallel rebuild. A twelve-person team might manage it with clear ownership. Team size constrains the viable approach more than most planning conversations acknowledge.
React Migration Strategy: Which Approach Fits Your Situation
Use this table to pressure-test your instinct before committing resources. Match your situation to the recommended approach, and treat it as the starting point for a conversation with your team, not the end of one.
| Situation | Recommended Approach |
|---|---|
| Legacy system live in production with active users | Incremental (Strangler Fig) |
| New features still being added to the old system | Incremental (Strangler Fig) |
| Existing codebase is modular with clear component boundaries | Incremental (Strangler Fig) |
| Old framework is unmaintained, bridging is prohibitively costly | Full rewrite with locked scope |
| No active user traffic (internal tool, admin panel, low stakes) | Full rewrite |
| Hard deadline, fully locked feature scope | Full rewrite |
| Team is under six frontend engineers | Incremental (Strangler Fig) |
| Team is large enough to staff parallel tracks | Either, with dedicated ownership |
The right call depends on your specific codebase, team composition, and constraints. What the table does is eliminate the option that clearly does not fit before you have committed time and headcount to it.
Five Reasons JavaScript Modernization Projects Actually Collapse
Most post-mortems on failed legacy modernization efforts circle back to the same handful of problems. These are not edge cases. They are the default failure modes.
- Underestimated state complexity. Global state wired through jQuery or direct DOM manipulation does not map cleanly onto a component model. The transition surfaces this complexity; it does not create it. If you have not audited your state management before starting, you will hit this wall mid-project. Plan for it explicitly, especially on forms, filters, and anything touching multiple data sources.
- SEO disruption from the switch to client rendering. Server-rendered pages often carry stable organic traffic signals. Moving to a client-side SPA can disrupt URL structures, page rendering behaviour, and Core Web Vitals all at once. If your application drives any meaningful search traffic, the plan needs an explicit SEO preservation layer before a single route is touched. Search engines do not pause ranking while you modernize.
- Unowned routing during coexistence. When both systems are live simultaneously, the routing layer needs a named owner. It sounds administrative. It becomes a crisis when the old application has hundreds of undocumented routes and the new build makes assumptions about paths that were never written down. A route audit before day one saves weeks of debugging.
- Deferred authentication coexistence. If the old system and the new application need to share session state or auth tokens, that integration needs to be solved early. Teams that resolve auth in week one run significantly smoother projects than teams that treat it as something to figure out later. Later always comes at the worst moment.
- No dedicated owner on the initiative. The most consistent pattern in stalled modernization projects: the work runs in the background alongside normal sprint commitments. Sprints fill up with product features. Progress stalls at 40% for six months. A real initiative needs one person accountable for it, protected capacity every sprint, and an explicit definition of done per slice.
When React Is Not the Right Modernization Target
This is worth saying directly: moving to React is not always the correct answer for a legacy codebase.
If your team's primary stack is .NET and the existing interface is a relatively simple server-rendered surface, Blazor may be a better target than a JavaScript-based tool entirely. If your team already has strong depth in Vue or Angular, and the engineers who will own the new build are more fluent there, choosing the most widely adopted option adds a relearning cost without a corresponding technical benefit.
The ecosystem advantage here is real: it has the largest pool of available engineers globally, and hiring is meaningfully easier than niche alternatives. But that advantage only materialises if you can actually recruit into it, or if your current team can credibly build in it at production quality.
If your team is evaluating the backend stack alongside the UI layer, those decisions are often interrelated. For example, a Python-heavy team choosing between FastAPI, Django, and Flask for their backend while simultaneously picking a UI framework is making two connected calls, not one.
The target should be the framework your team can execute in with confidence. Not the one with the best conference talks, and not the one that will look impressive in a job post.
Realistic Timelines for Migrating to React from a Legacy Stack
Timeline estimates for these projects are consistently off by a factor of two. That single miscalibration is one of the primary reasons initiatives lose stakeholder confidence before they finish.
For a rough baseline:
| Project Type | Typical Timeline |
|---|---|
| Large enterprise system, complex business logic, dedicated team | 12 to 24 months |
| Mid-sized product, modular codebase, 4 to 6 engineers | 6 to 12 months (incremental) |
| Small internal tool, bounded scope, locked requirements | 2 to 4 months (full rewrite) |
The variables that reliably extend timelines: undocumented business logic buried in the old codebase, auth and state synchronisation across two live systems, and scope additions mid-project. All three are controllable before the work starts. Almost none of them are controllable once it is underway.
Frontend Architecture Decisions That Outlast the Modernization Effort
A legacy-to-React project is a good time to make the frontend architecture decisions the original codebase avoided. The transition itself is a forcing function. Once the routing layer exists, you have to decide how routing will work in the new system. Once the first slice goes live, you have to decide on state management, component library conventions, and testing strategy.
Teams that treat these as things to figure out later end up with a new application that accumulates the same technical debt as the old one, just faster. The teams that come out of a modernization effort with a codebase they actually want to work in are the ones that made these calls at the start, documented them, and held the line on them as new slices were added.
Decisions worth making before the work starts, not during:
- State management approach. Redux, Zustand, Context, or nothing centralised. Pick one and enforce it before the second slice ships.
- Routing ownership and URL conventions. Who owns the route map, and what URL structure does the new system follow?
- Component library. Custom primitives vs. an existing design system (Radix, shadcn, MUI). Changing this mid-project is expensive.
- TypeScript adoption policy. Strict from day one, or gradual? Gradual usually means never.
- Test coverage requirements per slice. Define what "done" means for each migrated slice before the work begins. Retrofitting tests after ten slices have shipped rarely happens.
These are not exciting to settle upfront. They are painful to retrofit six months in.
Why Most Legacy-to-React Projects Succeed or Fail Before a Line Is Written
Modernization decisions that go well share a recognisable pattern: the engineering leader made the call with a clear rationale, aligned stakeholders before starting, picked an approach that matched the team's actual capacity, and assigned full ownership to a named person.
The ones that go badly share a different pattern: the team started without consensus on approach, underestimated complexity, treated the initiative as a background activity, and discovered mid-way that the old system still had dependencies nobody had mapped.
No architectural pattern compensates for a poorly structured decision. The Strangler Fig is a solid default, but it still requires a named owner, a route audit completed before day one, resolved auth coexistence, and protected engineering capacity each sprint. The pattern gives you a path. The organisation has to actually walk it.
Most teams do not get stuck choosing a framework. They get stuck deciding whether to start, which approach to take, and how to keep the initiative moving once scope pressure arrives. If your codebase is genuinely slowing the team down and costing you in hiring and velocity, the effort is worth it. If you are doing it because something newer is popular, it may not be.
We work with engineering teams on React development for new builds and legacy modernization. If you are at the decision point and want an honest read on whether your situation fits the incremental or rebuild path, reach out and we will tell you what we have seen work.
Frequently Asked Questions About Legacy Frontend Migration to React
Should we rewrite our frontend in React or migrate incrementally?
Incremental migration using the Strangler Fig pattern is the safer default for any system that is live and serving users. Full rewrites are appropriate only when the codebase cannot be sliced into independent modules, when the old framework blocks coexistence, or when scope is fully locked with a fixed deadline.
How long does a legacy frontend migration to React take?
Timelines vary by system size and approach. Expect the estimates in the timeline table above to slip by a factor of two if the codebase has undocumented business logic, auth needs to be synchronised across two live systems, or scope changes mid-project. Build the timeline around the slowest constraint, not the fastest path.
What is the Strangler Fig pattern for React migration?
The Strangler Fig pattern runs the legacy application and the new React app in parallel behind a routing layer (reverse proxy or API gateway). New features are built in React. Old views are retired one by one until the legacy system has nothing left to serve. Martin Fowler coined the term based on a vine that gradually replaces its host tree.
When should an engineering team not migrate to React?
When the legacy system is not measurably hurting hiring, velocity, or maintenance. Also when the team's existing framework already has strong community support and the engineers who will own the new build are more productive in it. Switching frameworks purely for ecosystem popularity adds relearning cost without a corresponding gain.
What breaks during a legacy to React migration?
The most common failures are: underestimated state complexity from jQuery or DOM-based state, SEO disruption from switching to client-side rendering, unowned routing during the coexistence phase, deferred auth integration between old and new systems, and lack of a dedicated owner with protected sprint capacity.
How do you migrate a jQuery frontend to React?
The same Strangler Fig approach applies. A routing layer (typically a reverse proxy) directs traffic between the old jQuery views and new React components. New features are built in React; old views are retired as each slice is validated. The main challenge is that jQuery apps often have global state wired through the DOM, which requires careful auditing before migration begins.
Is a full frontend rewrite ever worth it?
Yes, but only when the conditions in the "When a Full Rewrite Is the More Defensible Choice" section above are met. The short version: if you can slice the codebase, go incremental. If you genuinely cannot, a locked-scope rewrite with a dedicated team is defensible. The distinction matters because open-ended rewrites are where most failures happen.
How to migrate from AngularJS to React without downtime?
Use the Strangler Fig pattern with a routing layer that keeps AngularJS serving existing routes while new React components handle new features and gradually replace old views. The challenge with AngularJS specifically is that its digest cycle and dependency injection do not coexist easily with React, so a clear boundary (usually at the route level, not the component level) is needed.

Procedure Team
Engineering Team
Expert engineers building production AI systems.