Frontend Performance Testing: Best Practices


You have been working hard to deliver all the features on the project, and suddenly one fine day the company’s Slack goes off with messages like “Our bundle is around 17MB”or “Our website is lacking speed”. You are scratching your head as to why you even got here in the first place. What did you miss?
This blog will walk you through some best practices for Frontend Performance and Testing. It will walk you through metrics you can calculate on your CI/CD pipelines to avoid those surprise attacks related to performance issues and React best practices for an optimized bundle.
Performance Testing and Metrics
Let’s start with performance testing, figuring out where your webpage’s performance stands and how we can improve it. For this, we will look into some metrics and some common ways to improve them, later we will look into how we can track those using Lighthouse with a hands on demo.
Time To Interactive (TTI)
The point at which the user is ready to interact with the UI. This metric helps with how much time the user will have to wait before experiencing the UI without a lag.
Developers often optimize for fast render times, sometimes at the expense of TTI. This might lead to one of two following things –
- user will be annoyed that the page is slow to respond
- the user assumes the page is broken and will likely leave
To provide a good user experience, sites should strive to have a Time to Interactive of less than 5 seconds when tested on average mobile hardware.
How to improve TTI?
- Remove unused scripts
- Clean and compress the Javascript and CSS Files
- Implement the Code Splitting for Javascript Assets
Total Blocking Time (TBT)
Measures the time for which the website is non-interactive, which is the time between the First Contentful Paint (FCP) and the Time To Interactive (TTI).
To provide a good user experience, sites should strive to have a Total Blocking Time of less than 200-300 milliseconds when tested on average mobile hardware.
Total Blocking Time (TBT) is also related to the Time to Interactive (TTI). If the main thread of the browser doesn’t encounter a long task for 5 seconds, Time to Interactive happens. Time to Interactive is a necessary metric for understanding when the web page is “fully” and “continuously” interactive.
Let’s examine the example below, to understand this situation, better.
If there are only five long tasks that take 51 MS for the browser’s main thread that spread out to 12 seconds during the loading of the web page, it means that our TTI will happen in the 17th second of the loading. Without the Total Blocking Time, we couldn’t understand when and in which proportion the browser lets the user interact with the web page. In this example, the Total Blocking Time is only 3 MS. It means that most of the time, users can interact with the web page without notice of a significant delay. To understand and measure the User Experience (UX) and Load Responsiveness, Total Blocking Time and Time to Interactive should be used together.
How to improve TBT?
- Reduce the Request Count of the Third-Party Scripts
- Reduce the Size of the Third-Party Scripts
- Minimize the Browser’s Main Thread Work
- Clean the Unused Javascript and CSS Codes
- Compress the Javascript and CSS Files
- Implement the Code Splitting for Javascript Assets
Largest Contentful Paint (LCP)
Measures the time to render the most significant element visible on the viewport.
To provide a good user experience, sites should strive to have the Largest Contentful Paint of 2.5 seconds or less. To ensure you’re hitting this target for most of your users, a good threshold to measure is the 75th percentile of page loads, segmented across mobile and desktop devices.
What elements are considered in LCP?
'<img>'elements-
'<image>'elements inside an'<svg>'element '<video>'elements (the poster image is used)-
An element with a background image loaded via
the
'[url()](https://developer.mozilla.org/docs/Web/CSS/url())'function (as opposed to a CSS gradient) - Block-level elements containing text nodes or other inline-level text elements children.
- Important:- Images that occupy the entire viewport are not considered LCP candidates.
Additional elements like ‘<video>’ may be added in the
future as more research is conducted.
How is an element’s size determined?
- The size of the element reported is usually the size that is visible to the user within the viewport
- If the element extends outside of the viewport, or if any of the element is clipped or has non-visible Overflow, those portions do not count toward the element’s size.
- For image elements that have been resized, the size is either the visible size or the intrinsic size, whichever is smaller. For example, images that are shrunk down will only report the size they’re displayed at, whereas images that are stretched or expanded to a larger size will only report their intrinsic sizes.
- For text elements, only the size of their text nodes is considered (the smallest rectangle that encompasses all text nodes).
- For all elements, any margin, padding, or border applied via CSS is not considered.
How to improve LCP?
To start looking for opportunities to optimise LCP, you should look at these two places
- The initial HTML document
- The LCP resource (if applicable)
While other requests on the page can affect LCP, these two requests — specifically the times when the LCP resource begins and ends—reveal whether or not your page is optimized for LCP.
To identify the LCP resource, you can use developer tools (such as Chrome DevTools or WebPageTest) to determine the LCP Element, and from there you can match the URL (again, if applicable) loaded by the element on a Network Waterfall of all resources loaded by the page.
For a well-optimized page, you want your LCP resource request to start loading as early as it can. A good rule of thumb is that your LCP resource should start loading at the same time as the first resource loaded by that page.

Some of the examples to improve LCP can be –
- If the most significant element is an image, it should ideally be present on the initial HTML.
-
If it has a background image, you can prefetch the CSS.
<link **rel="preload" fetchpriority="high"** href="link_to_bg_image">
Cumulative Layout Shift (CLS)
This metric highlights the unexpected layout shifts when using the website.
Ever been to a website where you are about to do something suddenly now you are lost because the website auto scrolled to a different point on the page? Checkout the Cumulative Layout Shift Example Video Here.
Such unexpected movements of page content are measured with help of Cumulative Layout Shift (CLS). But also not all layout shifts are bad, they are bad only if the user isn’t expecting it. On the other hand, layout shifts that occur in response to user interactions (clicking a link, pressing a button, typing in a search box and similar) are generally fine.
For example, if a user interaction triggers a network request that may take a while to complete, it’s best to create some space right away and show a loading indicator to avoid an unpleasant layout shift when the request completes. If the user doesn’t realize something is loading, or doesn’t have a sense of when the resource will be ready, they may try to click something else while waiting—something that could move out from under them.
To provide a good user experience, sites should strive to have a CLS score of 0.1 or less. To ensure you’re hitting this target for most of your users, a good threshold to measure is the 75th percentile of page loads, segmented across mobile and desktop devices.
What are the most common causes of poor CLS?
- Images without dimensions
- Ads, embeds, and iframes without dimensions
- Dynamically injected content
- Web Fonts causing FOIT/FOUT
- Actions waiting for a network response before updating DOM
How to improve CLS?
-
Always add size attributes to your images and video elements so the browser
will reserve the place for them before they load.
<link **rel=“preload” fetchpriority=“high”** href=“link_to_bg_image”> - Always add minimum heights to the section that might expand on loading the data asynchronously.
- Reverse space for the ads, embeds, and iframes.
- Avoid inserting new content above existing content.
-
Preload fonts for more details read Preload Optional Fonts.
<link **rel="preload"** href="link_to_font">
Speed Index
Speed Index measures how quickly content is visually displayed during page load. Lighthouse first captures a video of the page loading in the browser and computes the visual progression between frames. Lighthouse then uses the Speedline Node.js Module to generate the Speed Index score.
Your Speed Index score is a comparison of your page’s speed index and the speed indices of real websites, based on Data From The HTTP Archive.
How to improve your Speed Index score?
While anything you do to improve page load speed will improve your Speed Index score, addressing any issues discovered by these Diagnostic audits should have a particularly big impact:
- Minimize Main Thread Work
- Reduce JavaScript Execution Time
- Ensure Text Remains Visible During Webfont Load
First Input Delay
FID measures the time from when a user first interacts with a page to the time when the browser is actually able to respond to that interaction.
To provide a good user experience, sites should strive to have a First Input Delay of 100 milliseconds or less. To ensure you’re hitting this target for most of your users, a good threshold to measure is the 75th percentile of page loads, segmented across mobile and desktop devices.
How to measure FID?
FID is a metric that requires a real user to interact with your page. You can measure FID with the following tools.
- Chrome User Experience Report
- PageSpeed Insights
- Search Console (Core Web Vitals Report)
- ‘[web-vitals’ JavaScript library](https://github.com/GoogleChrome/web-vitals)
-
You can measure FID in javascript by using the snippet below
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
const delay = entry.processingStart – entry.startTime;
console.log(‘FID candidate:’, delay, entry);
} }).observe({type: ‘first-input’, buffered: true});
How to improve FID?
- Keep requests and transfer sizes minimal
- Reduce third-party code, and JavaScript execution time
The guidance for improving FID is almost the same as that for improving Total Blocking Time (TBT).
First Contentful Paint
The First Contentful Paint (FCP) metric measures the time from when the page
starts loading to when any part of the page’s content is rendered on the
screen. For this metric, “content” refers to text, images (including
background images), ‘<svg>’ elements, or non-white
‘<canvas>’ elements.
To provide a good user experience, sites should strive to have a First Contentful Paint of 1.8 seconds or less. To ensure you’re hitting this target for most of your users, a good threshold to measure is the 75th percentile of page loads, segmented across mobile and desktop devices.
How to improve FCP?
- Minify CSS
- Remove unused CSS
- Reduce server response times
- Serve static assets with CDNs
How to measure these metrics?
We will be using Lighthouse to measure these metrics. Lighthouse is an open-source, automated tool for improving the quality of your web apps developed by Google.
You can use lighthouse in the following ways:
- You can calculate most of these metrics easily with the Lighthouse extension.
- Or you can set up a CI process on Github
Lighthouse Extension
- Go and download Lighthouse Extension
- Open Lighthouse and click on generate a report
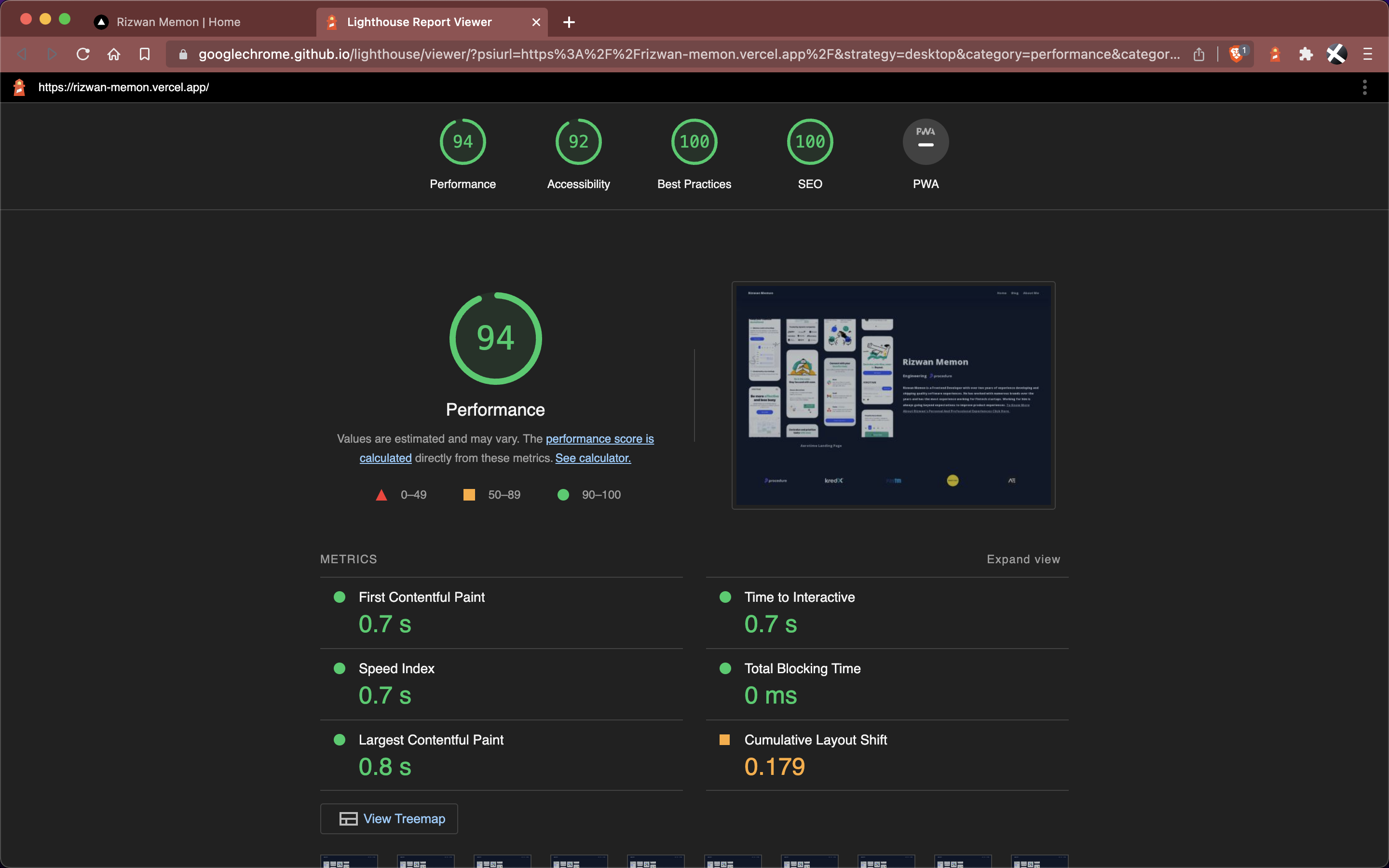
- A report will be generated with most of the metrics mentioned above
Lighthouse CI process on Github
-
In the root of your repository, create a directory named
‘.github/workflows’ -
In
‘.github/workflows’create a file named‘lighthouse-ci.yaml’. This file will hold the configuration for a new workflow. -
Add the following text to
‘lighthouse-ci.yaml’name: Build project and run Lighthouse CI
on: [push]
jobs:
lhci:
name: Lighthouse CI
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Use Node.js 10.x
uses: actions/setup-node@v1
with:
node-version: 10.x
- name: npm install
run: |
npm install
- name: run Lighthouse CI
run: |
npm install -g @lhci/cli@0.3.x
lhci autorun --upload.target=temporary-public-storage || echo "LHCI failed!"
This configuration sets up a workflow consisting of a single job that will run whenever new code is pushed to the repository. This job has four steps:
- Check out the repository that Lighthouse CI will be run against
- Install and configure Node
- Install required npm packages
- Run Lighthouse CI and upload the results to temporary public storage.
- Commit these changes and push them to GitHub. If you’ve correctly followed the steps above, pushing code to GitHub will trigger running the workflow you just added.
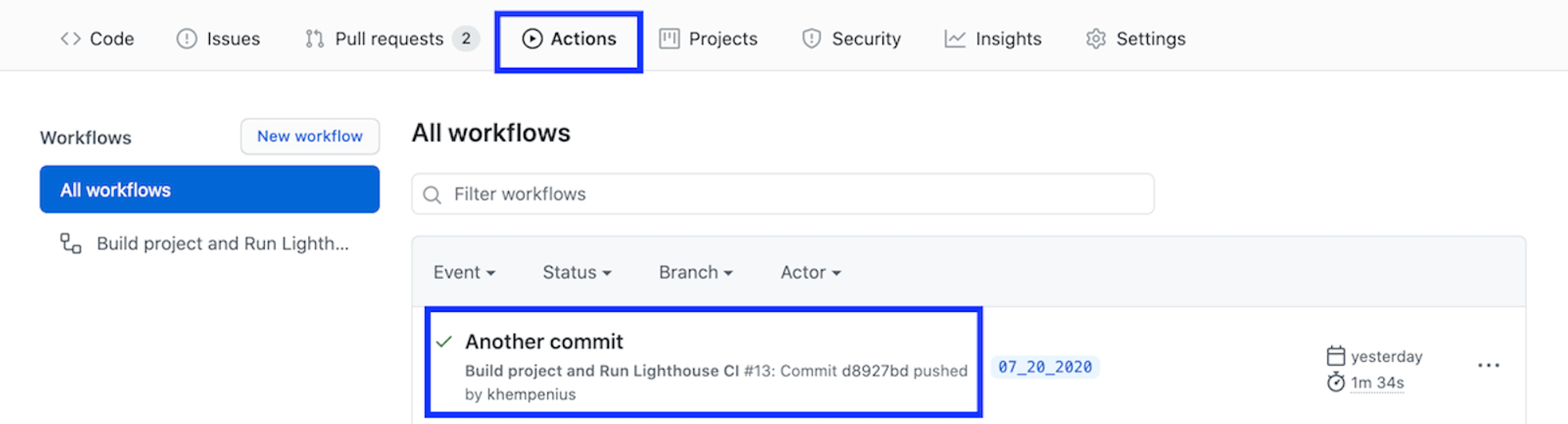
- To confirm that Lighthouse CI has triggered and to view the report it generated, go to the Actions tab of your project. You should see the Build project and Run Lighthouse CI workflow listed under your most recent commit
Throttling Performance
Not everyone in the world might have shiny M1 MacBooks like you. They do not represent average user performance for your app. Make sure you test your application across the most common devices.
Gather data about the most used devices for your application, and test your application on them using something like Browserstack. Or at the very least, do a set of performance tests while throttling CPU and network performance from dev-tools.
Optimizing Performance
Let’s talk about actually optimising performance, principles you can keep in your mind for performance issues, and building lightning-fast applications.
Optimizing assets
- Trying to use responsive images, I see many people forget to optimize images for mobile. You do not need that crispy 8K on a mobile device. Always swap to a lower resolution for mobile. Want to learn more read responsive images on MDN web docs.
- Use WebP / AVIF formats for your assets. Webp format helps reduce payloads, and AVIF outperforms JPEG in a very significant way. One of the best guides for optimizing images on the internet might be Maximally optimizing image loading for the web
- Optimize your JPEG/PNG/SVGs. Use tinypng for WebP, JPEG, or PNGs and SVGOMG for SVGs.
-
Replace Gifs with looping HTML video or WebP. Gifs can sometimes impact your
performance, if you can use them as fallbacks only
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>
Code Splitting
-
Using Dynamic Imports
Code Splitting is perhaps one of the important optimization parts. The best way to introduce code-splitting into your app is through the dynamic
'import()'syntax.Before
import { add } from './math'; console.log(add(16, 26));After
import("./math").then(math => { console.log(math.add(16, 26)); });When Webpack comes across this syntax, it automatically starts code-splitting your app. If you’re using Create React App/Next App.
-
Using
'React.lazy'The
'React.lazy'function will help you lazy load components using a dynamic importimport OtherComponent from './OtherComponent';After
const OtherComponent = React.lazy(() => import('./OtherComponent'));The lazy component should then be rendered inside a
'Suspense'component, which allows us to show some fallback content (such as a loading indicator) while we’re waiting for the lazy component to load.import React, { Suspense } from 'react'; const OtherComponent = React.lazy(() => import('./OtherComponent')); const Component = () => { return ( <div> <Suspense fallback={<div>Loading...</div>}> <OtherComponent /> </Suspense> </div> ); }The
'fallback'prop accepts any React elements that you want to render while waiting for the component to load. You can place the'Suspense'component anywhere above the lazy component. You can even wrap multiple lazy components with a single'Suspense'component. -
Loading separate CSS, and JS files in bundles
How you choose to bundle your applications also plays an important role in the performance and bundle size. I always suggest keeping JS and CSS as different files in your build.
-
Purging CSS
Remove all unused CSS. There are tools out there for doing so PurgeCSS and if you are using PostCSS already CSSNano
Memorization
-
React.Memo
'React.memo'is a Higher Order Component.
If your component renders the same result given the same props, you can wrap it in a call to'React.memo'for a performance boost in some cases by memoizing the result. This means that React will skip rendering the component, and reuse the last rendered result.const MyComponent = React.memo(function MyComponent(props) { /* render using props */ });'React.memo'only checks for prop changes. If your function component wrapped in'React.memo'has a'[useState](https://reactjs.org/docs/hooks-state.html)','[useReducer](https://reactjs.org/docs/hooks-reference.html#usereducer)'or'[useContext](https://reactjs.org/docs/hooks-reference.html#usecontext)'Hook in its implementation, it will still rerender when state or context change. -
useMemo hook.
The'[useMemo](https://reactjs.org/docs/hooks-reference.html#usememo)'Hook lets you cache calculations between multiple renders by “remembering” the previous computation. This helps you avoid re-calculating expensive computations.const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
Pagination
Make sure to implement pagination on the Backend when returning a list of data. Sending loads of data in the response might cause performance issues.
Debounce
Debouncing is a strategy that lets us improve performance by waiting until a certain amount of time has passed before triggering an event. When the user stops triggering the event, our code will run.
In some cases, this isn’t necessary. But, if any network requests are involved, or if the DOM changes (eg. re-rendering a component), this technique can drastically improve the smoothness and performance.
I usually prefer to use debounce provided by loadash but if you want to implement your own debounce function here is a snippet.
const debounce = (callback, wait) => {
let timeoutId = null;
return (...args) => {
window.clearTimeout(timeoutId);
timeoutId = window.setTimeout(() => {
callback.apply(null, args);
}, wait);
};
}
Conclusion
That covers most things you could start monitoring to never lead to performance issues. I hope you learned a thing or two reading this. Thank you for making it this far. If you have any questions or want to connect with us, head over to our LinkedIn.
Share




Latest Posts
May 26, 2022 | Rucheta Gogte
Why Robot Framework
If you are trying to identify what are the best automation frameworks out there, we…
ReadJanuary 3, 2022 | Sreeraj Rajan
Reducing our Deployment times by 87%
You can streamline your deployment process, decreasing deploy times significantly and enabling faster rollbacks with…
ReadJune 10, 2021 | Sreeraj Rajan
Connecting Django to RDS via pgbouncer using IAM auth
To connect Django to RDS via using IAM, you'll need an OIDC provider and a…
Read