Summary
School districts rely on accurate staff, course, and student data to generate schedules, but Timely’s previous setup required a separate data pipeline for every new district. As adoption grew, this approach slowed onboarding, repeated bugs across pipelines, and caused delays in data refreshes from SIS systems.
We helped redesign the system around SIS-level, reusable pipelines instead of district-level builds. This eliminated duplicate code, allowed new districts to onboard in days, and ensured no downtime during rollout. Today, the scheduling platform powers 30+ districts with cleaner data, faster syncs, and engineering time freed for core product work.
About The Client
Timely is an EdTech company focused on modernizing how middle and high schools create academic schedules. Their platform helps school leaders balance courses, staffing, classrooms, and student needs through a data-driven, automated timetable-creation process. By simplifying one of the most operationally complex processes in education, Timely enables schools to plan more efficiently, respond to changes faster, and deliver better learning continuity for students.
Country: United States
Team Size: ~30–40 people
Problem
Timely operates at the district level, but each school chooses whether to use the platform. Districts typically start with a small pilot group of schools and expand based on the feedback received. However, each district shared data in different formats, requiring custom data-processing pipelines, leading to repeated engineering work, data inconsistencies, and slow updates. As more districts joined, onboarding became harder to scale, and schools couldn’t see updates in Timely when they needed them.
Scope
Timely brought us in to build the first market-ready version and then scale it for multiple US districts. Our role covered the core web app, backend services, data ingestion and export flows from Student Information Systems (SIS), and the setup of monitoring to ensure reliable, trackable data syncing.
The Challenge
Timely’s data onboarding process worked for the first few school districts, but started breaking at scale. Each new district required a fresh data pipeline, and fixing a bug in one often meant fixing it in several others. This created mounting technical debt and slowed down the delivery of new features.
The bigger issue was timing. Schools updated their SIS data during the day, but those changes wouldn’t reflect in Timely until hours later, sometimes after 6 PM. Operations teams needed real-time accuracy to make scheduling decisions, but the system couldn’t keep up as more districts signed on.
Our Approach
Instead of continuing to build one-off pipelines for every district, we stepped back and studied how schools were sending data. We noticed most transformations weren’t district-specific but depended on the SIS they used. So we redefined the pipeline strategy at the SIS level, introduced strict data contracts and validation, and planned drop-in replacements to ensure schools experienced no downtime during migration.
The Solution
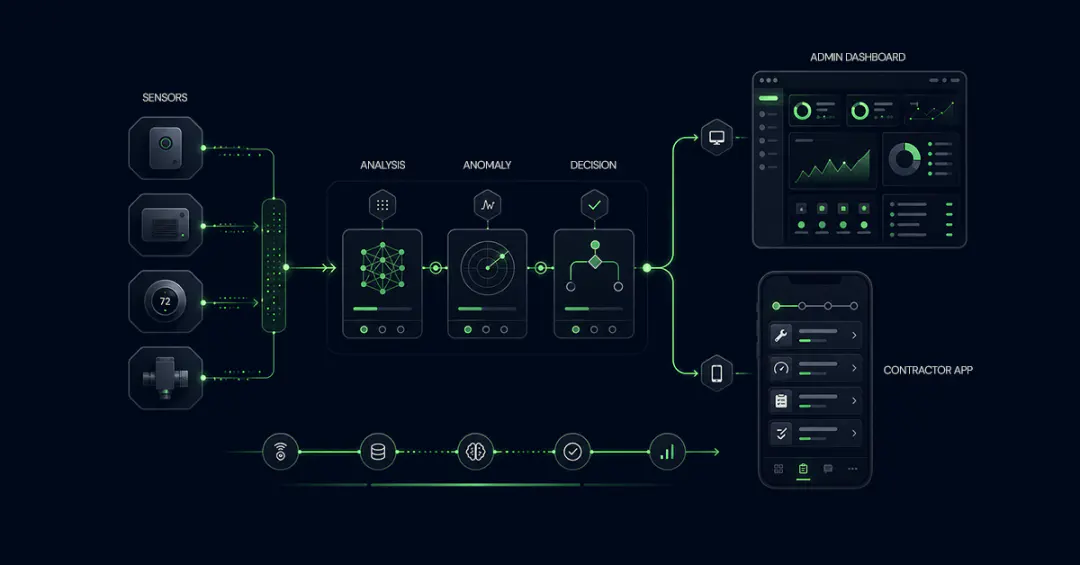
We built modular data pipelines that worked at the SIS level, allowing multiple districts to use the same logic instead of creating and maintaining separate pipelines. A validation and transformation layer cleaned and standardized incoming source data before it entered the scheduling engine. Ingest and export flows were made uniform across districts, and monitoring was added to track pipeline failures, stale data, and sync health in real time.
What We Built
We designed a reusable data architecture that moved the client away from one-off, district-specific pipelines:
- A modular SIS-level pipeline framework that multiple districts can share
- Data transformation and validation engine to clean and standardize raw CSV inputs
- Unified ingest and export flows to move data reliably into and out of the scheduling system
- Automated test coverage for schema accuracy, referential integrity, and pipeline reliability
- Monitoring and alerting layer to track sync health, failures, and data freshness in real time
How We Built It
We treated pipelines like products, designed for reliability, reuse, and zero disruption.
| Step | Process | Why It Mattered |
|---|---|---|
| 1. Studied existing pipelines | Analyzed 10+ district flows to find shared patterns across SIS platforms | Helped identify a scalable abstraction instead of one-off fixes |
| 2. Shifted to SIS-level design | Built pipelines per SIS, not per district | Reduced duplicated effort and made the new onboarding predictable |
| 3. Added contracts and automated tests | Introduced schema validation, referential checks, and test datasets | Prevented bad data from breaking schedules or causing silent errors |
| 4. Rolled out with zero disruption | Ran new pipelines in shadow mode, then switched over gradually | Enabled migration without downtime or impact on school operations |
| 5. Instrumented monitoring | Set up alerts for freshness, sync failures, and pipeline health | Allowed proactive resolution instead of reactive firefighting |
The Results
The shift from school-specific pipelines to a scalable foundation made district onboarding faster, reduced engineering rework, and enabled updates to roll out without any disruption. Data became more reliable for staff, and engineering teams could finally focus on new scheduling features instead of fixing pipelines.
- District onboarding improved by 25% for new SISs and 60% for districts on already-supported SISs
- Zero downtime during pipeline transitions or rollouts
- Duplicate pipeline engineering effort completely eliminated
- Data updates became more reliable across all schools
- Teams shifted focus from maintenance to core product development
| Result | Impact |
| 30+ School Districts | Actively onboarded and supported |
| 3–4 Days | Onboarding time for supported SIS districts |
| ~1 Week | Onboarding time for new SIS types |
| 50% Less Code | Reduction in pipeline maintenance overhead |
| 0 Downtime | During migration to the new pipeline system |
Why Procedure?
Scalable Data Systems, Not One-Off Pipelines
Most teams solve data problems district-by-district. We don’t. We identify repeatable patterns and build modular SIS-level pipelines that multiple schools can use immediately. This cuts duplicate engineering effort, keeps the codebase maintainable, and makes adding new districts or even entirely new SIS platforms far easier and faster.
Built Around How Schools Actually Operate
School systems don’t run on sprint cycles; they run on academic calendars, enrollment windows, and scheduling deadlines. Our delivery was planned around those rhythms. Features, data refresh capabilities, and pipeline releases were timed to support operations teams when they’re making real decisions, not after.
Zero-Disruption Rollouts, Even at Scale
Schools can’t afford broken schedules or data delays mid-semester. So every new pipeline was rolled out as a drop-in replacement, shadow-tested, validated, and monitored before going live. No outages, no manual backfills, no support tickets from districts. Existing schools continued running smoothly while the system evolved underneath.