Most Kubernetes teams do not wake up with a service mesh problem.
They wake up with something more specific. A security review asks how services authenticate each other. A production incident shows that nobody can explain why traffic moved the way it did. A team wants safer canary releases. A platform lead wants one place to manage retries, timeouts, and internal traffic rules instead of asking every service team to do it differently.
That is usually when someone asks, "Should we just add Istio?"
The honest answer is still: not always.
If you run a small number of services, one cluster, one or two teams, and you do not have a hard requirement for service-to-service encryption or traffic control, a service mesh will probably add more work than value. But the answer is less obvious than it used to be, because Istio ambient mode has changed the cost side of the decision.
The old sidecar model made the tradeoff visible. Every pod carried an extra proxy. Every rollout had one more moving part. Every debugging session had one more layer to inspect. Ambient mode changes that shape by moving the base secure layer out of every pod and into the node-level data plane.
That does not mean every team suddenly needs a mesh. It means teams that rejected service mesh earlier should revisit the decision with a better framework.
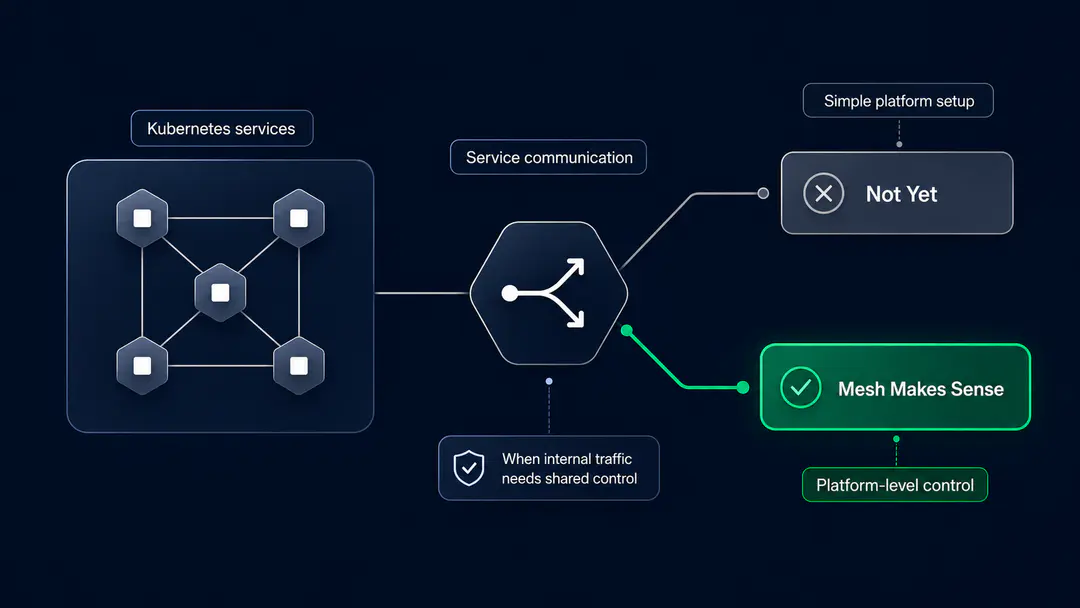
Do You Need a Service Mesh? The Short Answer
You need a service mesh when service-to-service communication has become important enough to manage at the platform level instead of inside every application. That usually means you need mTLS, workload identity, consistent traffic rules, network-level observability, or policy enforcement across many services and teams.
You probably do not need one if Kubernetes networking, an ingress controller, good application metrics, and a clear API gateway already solve your current problems.
The better question is not "Is a service mesh useful?" It is "Has internal service communication become expensive enough for us to standardize?"
What a Service Mesh Actually Does on Kubernetes (and What It Doesn't)
A service mesh is an infrastructure layer that manages communication between services without asking every application team to write the same networking, security, and traffic logic in code.
In practice, a service mesh usually gives you:
- mTLS between services, so workloads can prove who they are before talking to each other.
- Traffic management, so teams can control retries, timeouts, failover, canary releases, and routing rules.
- Network-level observability, so platform teams can see how services communicate even when application logs are incomplete.
- Policy enforcement, so teams can control which workloads are allowed to talk to which services.
- A shared control layer, so these rules do not live differently across ten repositories and five languages.
Istio's own service mesh concepts describe this as a way to add security, observability, and traffic control without changing application code. That is the useful part. The mesh sits between services and gives the platform a consistent way to manage how workloads talk.
But a service mesh has limits. It does not fix poor service boundaries or make a slow database fast. It does not replace application logs, traces, metrics, or incident reviews. And it does not remove the need for engineers who understand the system.
A service mesh helps when communication between services has become the problem. It hurts when the team is still struggling with basics like unstable deployments, missing health checks, unclear ownership, weak alerts, or fragile CI/CD.
The Economics Changed: Ambient Mode and the End of the Sidecar Tax
For years, the biggest argument against Istio service mesh adoption was operational, not technical. The feature set was rarely the problem. The cost of running and operating the mesh was.
The sidecar model asked every application pod to run an additional proxy. That gave teams powerful control, but it also added CPU, memory, startup complexity, upgrade friction, and debugging overhead. In small clusters, this felt unnecessary. In large clusters, it became a serious platform tax.
AWS App Mesh reaching its end-of-support path is one of the clearest signals that the older service mesh model did not work for everyone. It does not mean service mesh is dead. It means the "put a proxy beside every workload and absorb the cost everywhere" approach was never going to become the default for every Kubernetes team.
Istio ambient mode changes the cost model. Instead of injecting a sidecar proxy into every pod, ambient mode splits the data plane into two layers:
- ztunnel, which runs at the node level and handles the base secure service-to-service layer.
- Waypoint proxies, which are added only when a workload needs L7 features such as HTTP routing, advanced policy, or richer traffic control.
This matters because not every service needs the full mesh feature set.
Many teams mainly want encrypted service-to-service traffic and identity-based policy. For that, ambient mode can avoid putting a full proxy beside every application pod. When a team needs deeper L7 behavior, it can add waypoint proxies more selectively.
That is why ambient mode migration has become a real discussion for teams that dismissed Istio earlier. The cost is no longer automatically tied to the number of pods. It moves closer to the shape of the cluster and the features you actually use.
Ambient mode does not make service mesh free. You still need platform ownership, upgrade discipline, policy design, observability changes, and rollout planning. But it removes one of the biggest reasons teams avoided service mesh in the first place.
When to Use a Service Mesh: Five Questions That Decide It
Do not start with Istio, Linkerd, Cilium, or any other tool. Start with the pressure your system is already feeling.
Here is the decision framework.
1. How Many Services Do You Actually Run?
If you have 8 to 15 services, one cluster, and most traffic flows through a small set of APIs, a service mesh will usually add more work than value.
At that size, you can often get enough control from:
- Kubernetes NetworkPolicies
- An ingress controller or API gateway
- Good application metrics
- Clear service ownership
- Basic retries and timeouts in application code
- A small number of shared libraries
Once you cross 30, 50, or 100 services, the story changes. Service-to-service rules become harder to reason about. Different teams make different choices. Traffic paths get harder to trace. Security reviews start asking how services authenticate each other.
Treat the count as a signal rather than a hard rule. If every new service adds more communication risk, you are closer to needing a mesh.
2. Do You Have a Real mTLS or Compliance Requirement?
This is one of the strongest reasons to adopt a service mesh.
If your compliance, security, or customer requirements say that service-to-service traffic must be encrypted and authenticated inside the cluster, a mesh gives you a standard way to do that.
Without a mesh, teams often solve this unevenly. One service uses a library. Another relies on the platform. A third assumes internal traffic is trusted. Over time, that becomes difficult to explain and harder to audit.
A service mesh can give you workload identity and encrypted service communication as a platform default. This is where "do I need a service mesh" becomes less of an engineering preference and more of a governance decision.
3. Do You Have Multiple Teams or Multiple Clusters?
A service mesh becomes more useful when many teams own different services but still share the same runtime environment.
The mesh gives the platform team a way to define common traffic and security rules while letting product teams keep shipping. That can help larger engineering organizations where every service cannot invent its own approach to timeouts, retries, identity, and policy.
Multi-cluster setups make the case stronger, but also harder. If services span clusters, regions, or environments, the mesh can help standardize identity, policy, and routing. But it also increases the need for strong platform operations. A badly run multi-cluster mesh can become the thing everyone is afraid to touch.
Multiple clusters alone do not settle the question. The deciding factor is whether you have the team to operate shared networking across them.
4. Do You Have Platform Bandwidth to Own It?
A service mesh is not a one-time installation.
Someone has to own upgrades, test policies, and debug traffic when a rollout breaks. Someone has to understand how application behavior changes when retries, timeouts, mTLS, or L7 routing move into the platform layer.
This is where many teams get the decision wrong. They choose a mesh because they want fewer application teams dealing with networking. That part is fair. But the responsibility does not disappear. It moves to the platform team.
A service mesh is worth it only if the platform team can own it properly. If no one has time to maintain it, wait.
5. Are You Already Getting Enough L7 Control From an Ingress or Gateway?
Many teams confuse north-south traffic with east-west traffic.
An API gateway usually manages traffic entering the system from outside. A service mesh usually manages traffic between services inside the system.
If your biggest problems are authentication at the edge, public API rate limits, partner access, or routing traffic from the internet into your cluster, you may need an API gateway more than a service mesh.
If your biggest problems are service-to-service identity, internal retries, internal traffic policy, and communication visibility between workloads, a service mesh becomes more relevant.
Some teams need both. Many do not. Before adopting a service mesh, check whether your existing ingress, gateway, or platform layer already gives you enough control.
Service Mesh vs API Gateway vs Cilium vs App Libraries
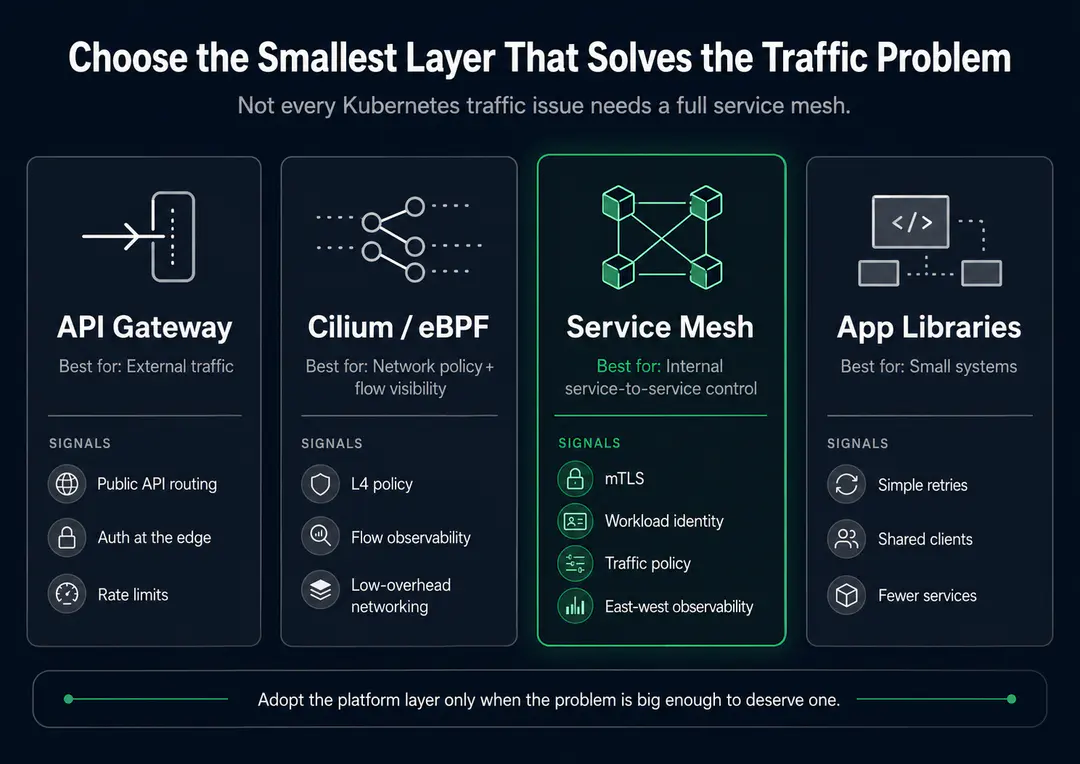
A lot of service mesh confusion comes from comparing tools that solve overlapping but different problems.
Here is the practical comparison.
| Option | Best for | Where it helps | Where it falls short |
|---|---|---|---|
| Service mesh | Internal service-to-service communication | mTLS, traffic policy, retries, workload identity, service-level routing, network-level observability | Adds platform complexity and needs active ownership |
| API gateway | External traffic entering the system | Auth, rate limits, public API routing, partner access, edge policies | Does not usually manage all internal service-to-service traffic |
| Cilium / eBPF networking | Kubernetes networking, security, L4 observability, policy, low-overhead data path | Network policy, encryption options, flow visibility, low-overhead traffic handling | May not replace every L7 traffic management feature a full mesh provides |
| In-app libraries | Smaller teams with fewer services | Simple retries, timeouts, auth wrappers, shared client logic | Becomes inconsistent across teams, languages, and services |
Service Mesh vs API Gateway
The simplest difference is direction.
An API gateway controls how clients enter your system. A service mesh controls how services inside your system talk to each other.
If a mobile app calls your backend, that is usually API gateway territory. If the payments service calls the orders service, and the orders service calls the inventory service, that is service mesh territory.
This is why "service mesh vs API gateway" is rarely a winner-takes-all comparison. A mature platform may use both. The gateway handles external access. The mesh handles internal service communication.
Where Cilium Fits
Cilium has changed the service mesh conversation because it covers a lot of the security and observability overlap at the network layer.
For many Kubernetes teams, Cilium already gives them strong network policy, visibility through Hubble, encryption options, and low-overhead eBPF-based traffic handling. That may be enough, especially if the team does not need the full L7 behavior of a mesh.
This is a good thing. It means teams have more choice.
If you mainly need network security, identity-aware policies, and visibility into flows, Cilium may cover enough ground without adopting a full Istio service mesh. If you need richer traffic control, L7 authorization, progressive delivery rules, or consistent service-level behavior across many teams, Istio or another mesh may still make sense.
A good Kubernetes platform decision is rarely about choosing the most powerful tool. It is about choosing the smallest platform layer that solves the real problem.
Linkerd vs Istio
Linkerd and Istio still get compared because both are established service mesh options.
Linkerd is often seen as simpler to start with. Istio is broader, more configurable, and more deeply tied to advanced traffic management, policy flexibility, Gateway API work, and ambient mode.
That does not make one universally better. If the team wants a lighter mesh with fewer moving parts, Linkerd may be attractive. If the team needs deep traffic control, multicluster support, ambient mode, or advanced platform policies, Istio usually becomes the stronger candidate.
Again, the decision should come from your operating needs, not from the popularity of the tool.
Istio Service Mesh: Sidecar vs Ambient, and the Migration Reality
By 2026, the harder Istio question is no longer whether to use Istio. It is which data plane to run: sidecars, ambient mode, or both during a transition.
Sidecars are familiar. A lot of tooling, dashboards, runbooks, and team knowledge grew around the sidecar model. For existing Istio users, that matters.
Ambient mode changes the shape of the data plane. ztunnel runs as a DaemonSet at the node level. Waypoint proxies are added when L7 behavior is needed.
With sidecars, cost scales with pods. More pods usually means more proxies. With ambient, the base layer scales more with nodes. ztunnel runs once per node, and waypoint proxies are introduced only for workloads that need them.
A rough mental model is this: when a node runs only a few pods, the difference may not feel dramatic. When a node runs 8 to 10 or more pods, ambient mode starts to look more attractive because you are no longer attaching a full sidecar to every pod just to get the base secure layer.
This is not a universal benchmark. Workload shape, node size, traffic volume, and feature usage all matter. But it is a useful way to think about the shift.
The migration reality is more boring than the architecture diagram.
You need to check:
- Which namespaces should enter the mesh first
- Which services only need L4 security
- Which services need L7 routing or authorization
- Which dashboards depend on sidecar-level telemetry
- Which alerts will change when the data plane changes
- Which teams own traffic rules after migration
- Which failure modes need a rollback path
The observability part often surprises teams. Existing metrics, traces, and dashboards may assume the sidecar model. Moving to ambient can change where signals come from and how teams interpret service traffic.
If you run Prometheus heavily, the mesh decision is also a monitoring decision. Our guide on Prometheus monitoring at scale covers the telemetry side that changes when you move the data plane.
The short version is simple: do not migrate everything because ambient mode exists. Migrate where the benefit is clear, keep sidecars where they still make sense, and give teams time to adjust their dashboards and runbooks.
Why Teams Are Revisiting the Service Mesh Decision for AI Workloads
There is another reason service mesh is back in the conversation. AI workloads are making traffic management strange again.
Traditional services are usually predictable. A request comes in, a few services talk to each other, and the response goes back.
AI workloads add new routing questions. Which model should handle this request? Which inference backend is healthy right now? Should the request go to a faster model, a cheaper model, or a fallback path? How should traffic move when GPU capacity changes, and how do you observe latency, cost, and reliability across model-serving paths?
That is why Gateway API Inference Extension is worth watching. It is meant to standardize routing to self-hosted AI models on Kubernetes. CNCF's 2026 Istio update points to Gateway API Inference Extension beta and experimental agentgateway support as part of Istio's direction for AI-era traffic management.
This does not mean every AI team needs a service mesh.
If you are calling hosted model APIs from a few backend services, a mesh is probably not your first problem. You may need better request tracing, cost visibility, queues, evals, and provider fallback before you need a mesh.
But if you are running model-serving workloads on Kubernetes, routing across inference backends, managing internal AI services, or building agentic systems where many services call each other, the mesh conversation becomes more relevant.
The same rule applies: adopt the platform layer when the traffic problem is big enough to deserve a platform answer.
The Verdict: When to Adopt a Service Mesh, and When to Wait
You should consider a service mesh on Kubernetes when your service-to-service communication has become too important, too distributed, or too risky to manage inside individual applications.
That usually means one or more of these are true:
- You have many services and teams.
- You need mTLS and workload identity by default.
- You need consistent traffic policy across services.
- You run multiple clusters or expect to soon.
- You need deeper service-to-service observability.
- You have a platform team that can own the mesh properly.
You should wait if:
- You have fewer than 20 services.
- One team owns most of the system.
- Your current gateway and observability setup are enough.
- You do not have a real mTLS or policy requirement.
- No one has bandwidth to operate the mesh after installation.
Ambient mode makes Istio easier to justify than it used to be, especially for teams that rejected sidecars because of resource and operational cost. But easier does not mean automatic.
The best service mesh decision is the one your team can explain six months later during an incident.
If you are unsure whether to adopt, migrate, or simplify your current setup, Procedure can help with an honest assessment of your mesh setup. The useful outcome may be Istio. It may be ambient mode. It may also be "do not add a mesh yet." That is still a good answer if it saves your team from carrying a platform layer it does not need.
Procedure's platform engineering team has designed and reviewed Kubernetes service mesh setups across production environments. Follow our engineering work on LinkedIn.
Frequently Asked Questions
Is a service mesh worth it for a small team?
Usually, no. A small team with fewer than 20 services can often get enough value from Kubernetes networking, an API gateway, application metrics, and a few shared libraries. A service mesh becomes worth considering when service-to-service security, traffic control, or observability needs to be managed consistently across many services.
Do you need Istio to run Kubernetes?
No. Kubernetes does not require Istio or any service mesh. You can run production Kubernetes workloads with ingress controllers, network policies, observability tools, and good deployment practices. Istio becomes useful when internal service communication needs stronger platform-level control.
What is the difference between a service mesh and an API gateway?
An API gateway manages traffic entering your system from external clients. A service mesh manages traffic between services inside your system. The gateway is usually responsible for edge concerns such as public API routing, authentication, and rate limits. The mesh is usually responsible for internal mTLS, service identity, traffic policy, and service-to-service observability.
Is Istio ambient mode production ready?
Istio ambient mode is a serious production option for teams that need its core data plane benefits, especially L4 security and workload identity. The right answer still depends on which features you need. Advanced L7, multicluster, and tooling workflows should be reviewed before migration.

Procedure Team
Engineering Team
Expert engineers building production AI systems.