Scaling Observability Platform with 42 Million Data Points per Minute During Live Sports
Summary
A leading observability platform needed engineering support at scale: 42 million telemetry data points per minute, a 99.9% SLA commitment, and live broadcasts across 3 tournament types where downtime was not an option. Procedure was brought in as an embedded team, owning frontend features, the alerting system, and war room operations on the ground at the client's office. The team shipped a critical dashboard feature in one week, maintained 95% platform uptime during tournament windows, and kept MTTR to 2-3 hours during live events.
About the Client
The client is an observability platform company that provides real-time monitoring for high-traffic applications, along with metrics ingestion and alerting for engineering teams running large-scale distributed systems. Their platform collects telemetry signals (logs, metrics, and traces) through standard pipelines like OpenTelemetry and Prometheus, and surfaces information about system health.
One of the platform's most demanding customers was a major live-streaming service that used it to monitor the health of its microservices during live sporting broadcasts.
The Problem
Live sporting events produce traffic patterns that no synthetic load test can fully replicate. A marquee matchup between popular teams can spike viewership far beyond projections. A dramatic in-game moment can push traffic even higher within seconds.
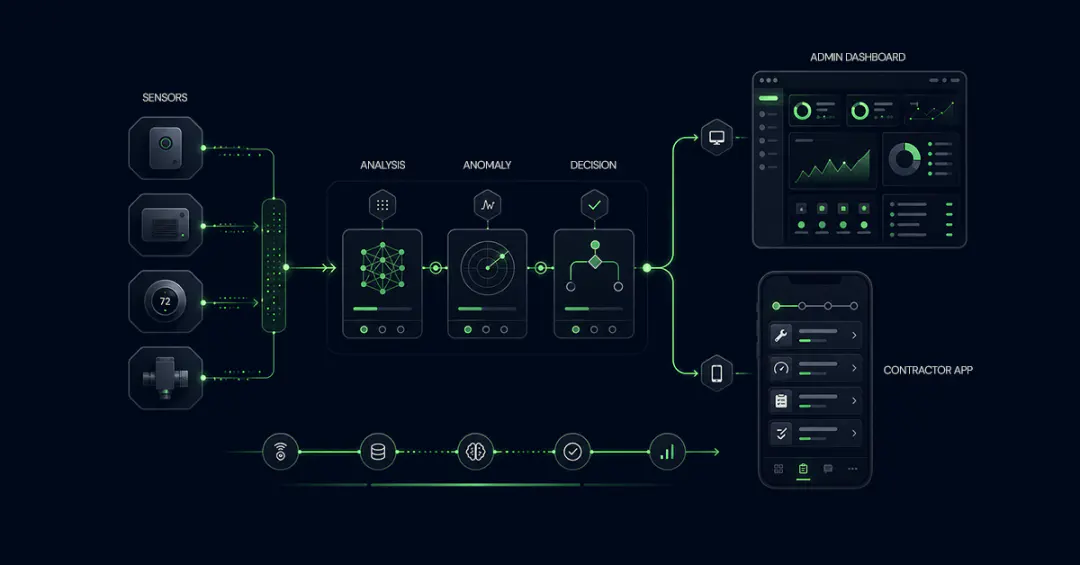
The observability platform had to ingest all of this telemetry in real time, because the client's engineering teams depended on real-time monitoring of high-traffic applications to keep their own systems running. Handling these bursts without lag or data loss was only part of the challenge. The platform also needed custom dashboards for live event tracking, infrastructure tuning across ingestion pipelines, and a coordinated operational model with the client's team.
The platform company needed engineers who could work across product development and live-event operations, embedded deeply enough to take ownership of customer-facing features.
The Scope
The observability platform engaged Procedure to embed an engineer directly within their core team, with full ownership of frontend features, the alerting system, and on-the-ground war room operations. The engagement covered:
- Frontend feature development, including dashboard and alerting UI work
- On-call operations and war room participation during live broadcasts
- Production debugging and incident response under match-time constraints
- Contributing to post-tournament incident reviews and reliability improvements
The engagement spanned multiple tournament cycles, including a premier national cricket league, T20 internationals, and World Cup events.
The Challenge
During a live sporting event, the streaming service's infrastructure emitted telemetry across many services and runtime components. These systems produced a large volume of metrics continuously, creating heavy ingestion pressure during peak viewership. Scaling observability for live events of this magnitude meant the platform had to sustain ingestion rates that peaked at 42 million telemetry data points per minute without degradation.
The operational side was just as demanding. Here is what a typical tournament window looked like:
Before the tournament: The streaming team shared estimated scale-up numbers for the first week's live events. These were rough estimates, because viewership during high-traffic events is inherently unpredictable. The observability platform had to be ready for the upper bound, because an SLA was in place.
The pre-tournament work included load testing from both the platform and the streaming team's side, experimenting with resource configurations using Terraform, allocating on-call roles, and shipping all requested features before a hard code-freeze date.
During the tournament: On every event day, systems were scaled up two hours before broadcast and scaled down an hour after the event ended. Ingestion targets came from the streaming team a day earlier. Scale operations were manual, adjusting storage, pods, and ClickHouse resources through Terraform configs.
Three parallel war rooms ran simultaneously during live streaming. The structure, defined by the platform's leadership, placed a forward-deployed engineer physically at the client's office. A second room had the platform engineering team coordinating with the streaming service's engineers. A third room had the platform team monitoring their own systems on standby. Any bugs or feature requests from the streaming team were prioritized above all other customer work. Communication flowed through Slack channels and PagerDuty for escalations.
After the tournament:
Critical incidents were reviewed, root-caused, and turned into preventive measures for the next cycle.
Our Approach
Procedure's engineer was embedded as a full team member, not an external consultant. They owned the frontend features end-to-end, the alerting system, and on-ground war room operations at the client's office.
Pre-tournament: The team ran load tests against the ingestion pipeline and experimented with resource tuning for different traffic scenarios. Procedure's focus was on shipping feature requests before the code-freeze deadline. The streaming service's CTO and senior engineers wanted a dashboard pinning feature: the ability to pin a specific dashboard to the home screen for quick access during events, instead of searching through all available dashboards each time. This was built and shipped in one week. Turnaround on feedback was fast, with the team iterating through the night to meet the code-freeze deadline.
Live-event operations: During broadcasts, Procedure's engineer monitored system health from the operations room at the client's office, triaged alerts, and coordinated across teams. The general rule was no production deployments during match time.
Incident debugging under pressure: In one case, Procedure's engineer found a frontend bug specific to the streaming service's workload, a calculation error in how alerts were grouped by service and team. It could not be reproduced in any test environment. The only path to validation was production. With the match live, the engineer deployed the frontend fix without prior approval.
The initial deployment broke, but the engineer debugged directly in production using stack traces, module bundles, and live console tools, and resolved the issue during the match window. Because it was a frontend-only change, there was no user-facing degradation to the monitoring service.
What We Built
| Deliverable | What We Did | Why It Mattered |
| Dashboard pinning feature | Built a one-click home screen pin for the streaming service's engineering leadership, shipped from request to production in one week under a hard code-freeze deadline. | Engineering leadership had instant access to their live-event system health view during broadcasts, no searching required. |
| Alerting system ownership | Owned the alerting frontend end-to-end, including a production bug fix for alert grouping logic specific to the client's service and team structure. | Alert accuracy was maintained for the streaming service's team during live events. |
| War room operations | Operated from the coordination room at the client's office during every event, triaging alerts and coordinating across teams via Slack and PagerDuty. | Issues were detected and escalated quickly during windows where downtime directly impacts viewer experience. |
| Post-tournament reliability | Contributed to incident postmortems and preventive measures after each tournament cycle. | Each season's learnings fed into the next cycle's preparation. |
Results
| Result | Detail |
| 42M Data Points/Min | Peak telemetry ingestion rate sustained during live broadcasts |
| 99.9% SLA | SLA target committed for live-event operations, largely met across tournament windows |
| 3 Tournament Types | Premier cricket league, T20 internationals, and World Cup events supported |
| 1-Week Feature Delivery | Dashboard pinning feature shipped from request to production in one week |
| 2-3 Hour MTTR | Average incident detection to resolution time during live events |
Why Procedure
We operate as your team, not alongside it.
In this engagement, Procedure's engineer sat in the client's office during live events, participated in operations rooms alongside the platform's core team, and made production-level decisions under pressure. That level of embedding is what makes the difference when a pager goes off during a live broadcast with millions of viewers.
We build for the constraints of live operations.
Code freezes, match-time deployment restrictions, and unpredictable traffic spikes are the reality of live-event infrastructure. When the only way to validate a fix is to deploy it during a live match, our engineers have the context and judgment to make that call.
We make observability engineering stronger over time.
Uptime during a single event is a baseline. Contributing to post-incident reviews after each tournament created a compounding effect, where every cycle's lessons fed into the next season's preparation. The result is an observability platform that gets better at handling peak load, not just one that survives it.